
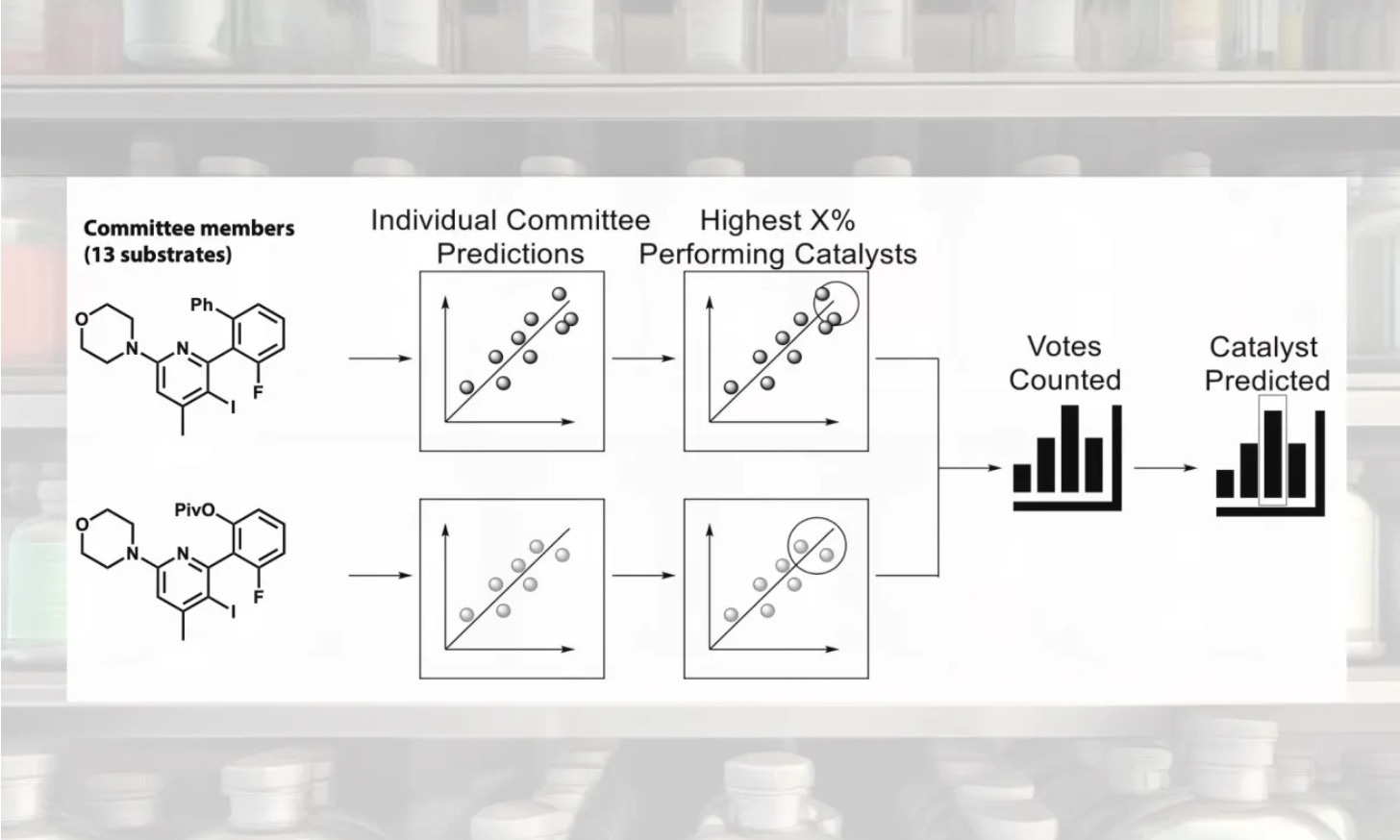
Prof. Scott E. Denmark et al. at the University of Illinois used three-dimensional molecular structures to enable machine learning to predict selectivity in asymmetric catalysis in 2019.[1] Later in 2022, they succeeded in developing a catalyst that exhibited high asymmetric yield using this workflow. This time, they not only used this workflow as it is, but they also made an innovation by using “voting”.
“High-Level Data Fusion Enables the Chemoinformatically Guided Discovery of Chiral Disulfonimide Catalysts for Atropselective Iodination of 2-Amino-6-arylpyridines.”
Rose, B. T.; Timmerman, J. C.; Bawel, S. A.; Chin, S.; Zhang, H.; Denmark, S. E.
J. Am. Chem. Soc. 2022, 144 (50), 22950-22964. DOI: 10.1021/jacs.2c08820
Overview
They used the machine learning workflow[1] to find an optimal catalyst 3d in an attempt to develop a new reaction for the asymmetric synthesis of atrope isomer 2 resulting from the iodination of phenylpyridine 1 (Fig. 1, top). The reason for working on the development of this reaction was that there was a drug discovery demand for the reaction, yet there was no effective means of achieving it.
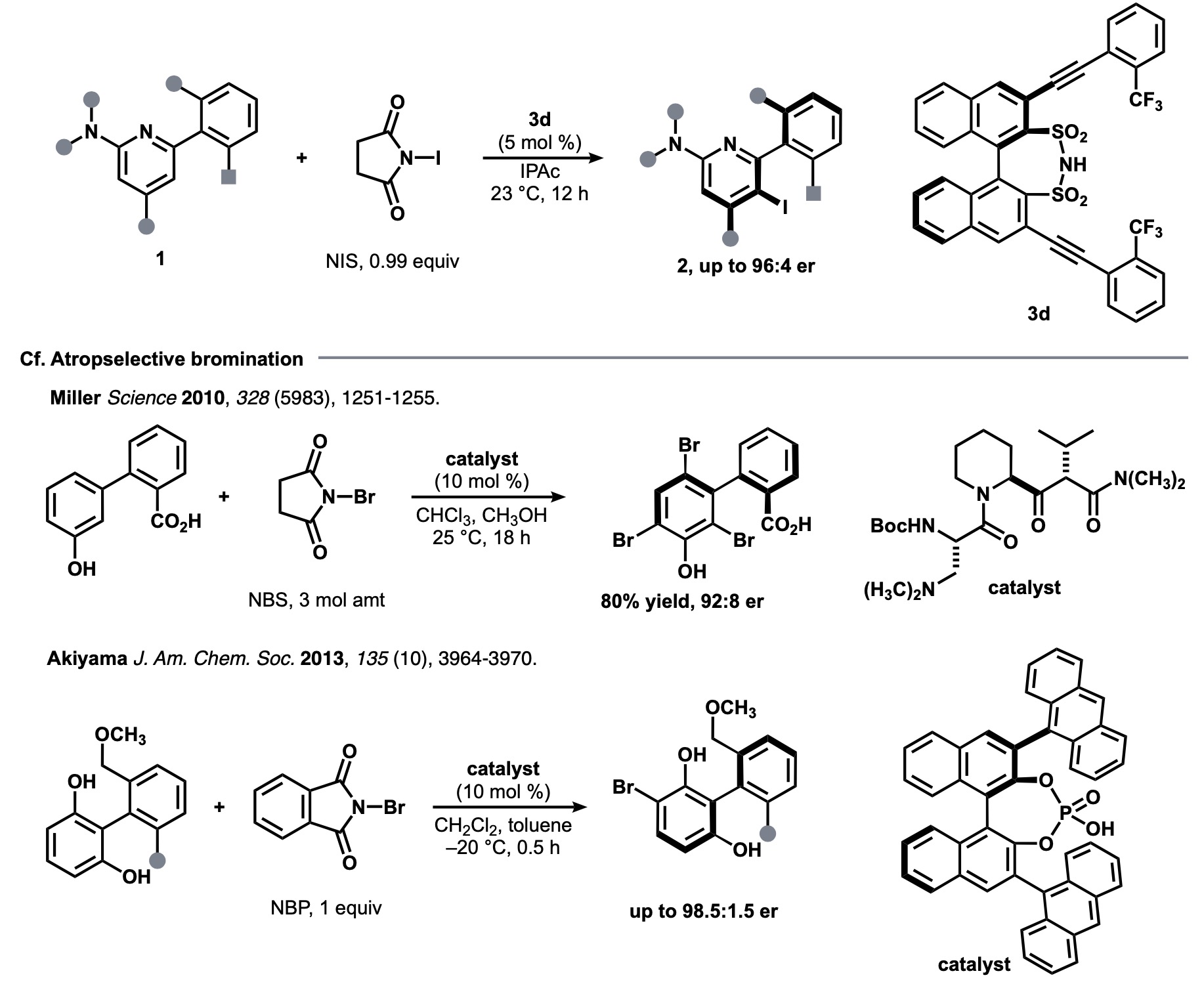
Figure 1. The current study (top) and related previous studies on bromination (bottom)
The related enantioselective bromination reaction had been developed by Miller and Akiyama et al. (Fig. 1, bottom). The Akiyama chiral phosphoric acid catalyst had given good results in a previous study by Denmark et al. So initially they tested the phosphoric acid catalyst but they found that enantiomeric ratio (er) was higher with sulfonimide 3a than with phosphoric acid (Fig. 2). As the enantioselectivity was not further improved in the condition optimization, and the enantioselectivity was not satisfactory for some substrates, they started the machine learning workflow described above to identify a catalyst with higher selectivity and versatility.
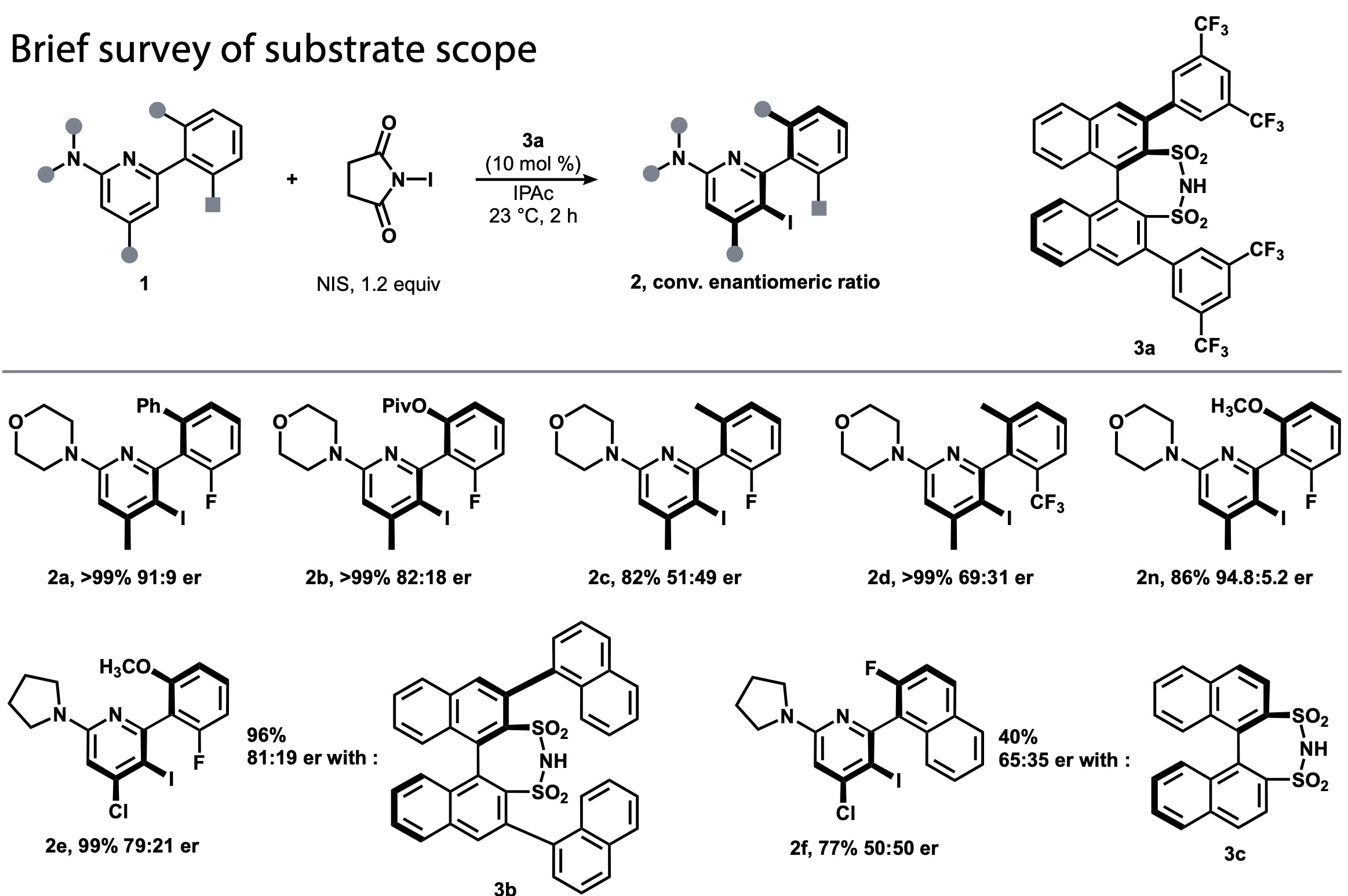
Figure 2. Substrate scope of enantioselective iodination reactions using 3a in the initial study.
Method
The following flow was used:
- Generate a Core of catalyst structures (using MM and DFT calculations): select binaphthyl 3 and hydrogenated binaphthyl 4
- Generate 1478 virtual catalyst libraries from 739 substituents (using ccheminfolib and python)
- Optimization (Maestro), generation of conformations (OPLS3e), and adjustment (change NH back to BH to do calculations in Maestro)
- Descriptors used in previous report [1]: average steric occupancy (ASO, 1 Å lattice) calculated (+ electronic state considerations)
- K-means clustering selected 21 catalyst candidates (universal training set), of which 18 were successfully synthesized (Fig. 3)
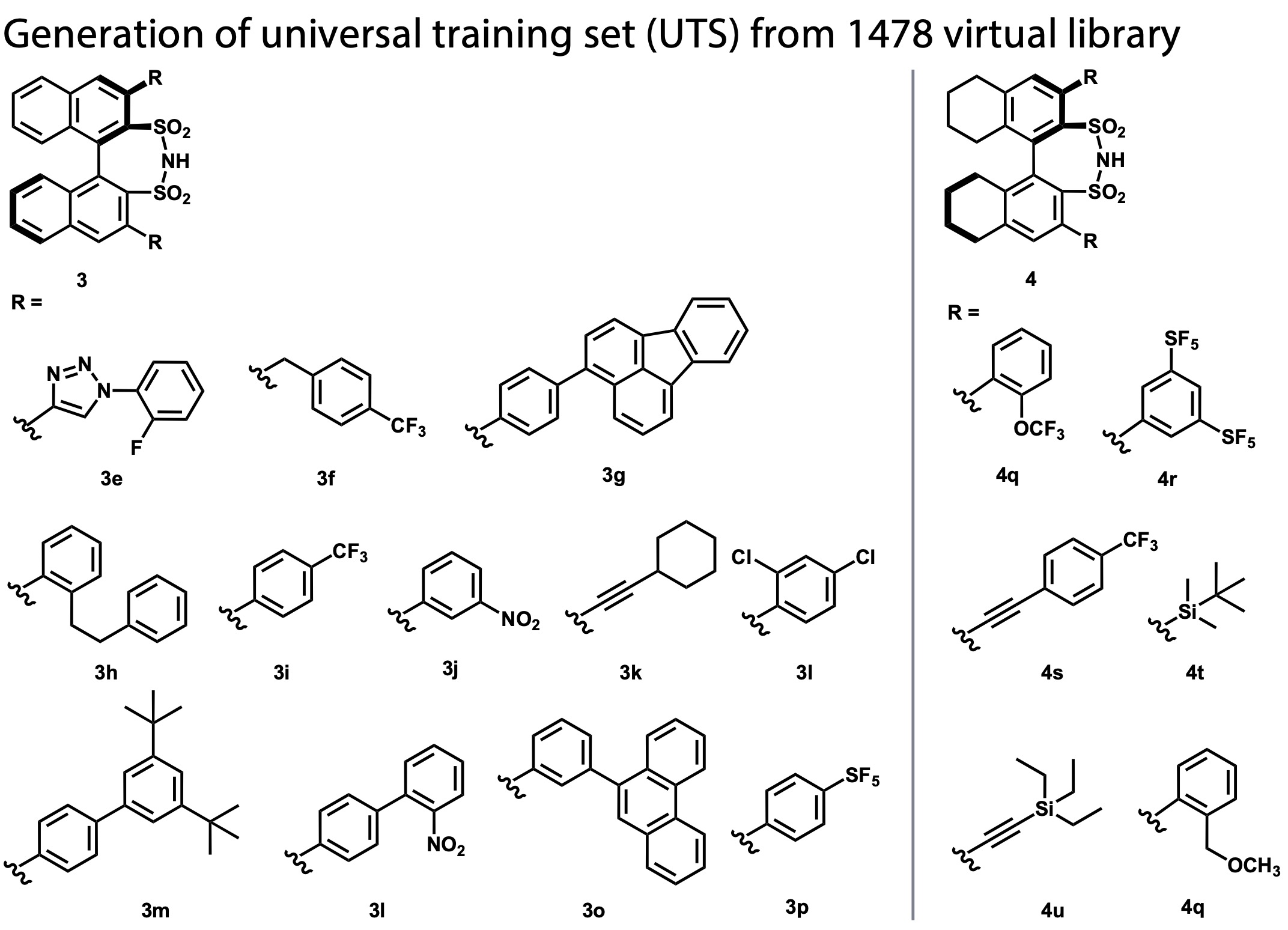
Figure 3. 18 catalysts selected and synthesized by clustering from the library
Result
They performed 234 experiments with 18 actual synthesized catalysts x 13 substrates. The reactions were performed by high-throughput equipment, and the analysis was performed by two-dimensional LC. Three catalysts, 4s, 4u, and 4t, were found to be good by machine learning based on the experimental results. Contrary to expectations, however, the catalysts resulted in low generality, although high enantioselectivity was expected for some substrates (Fig. 4).
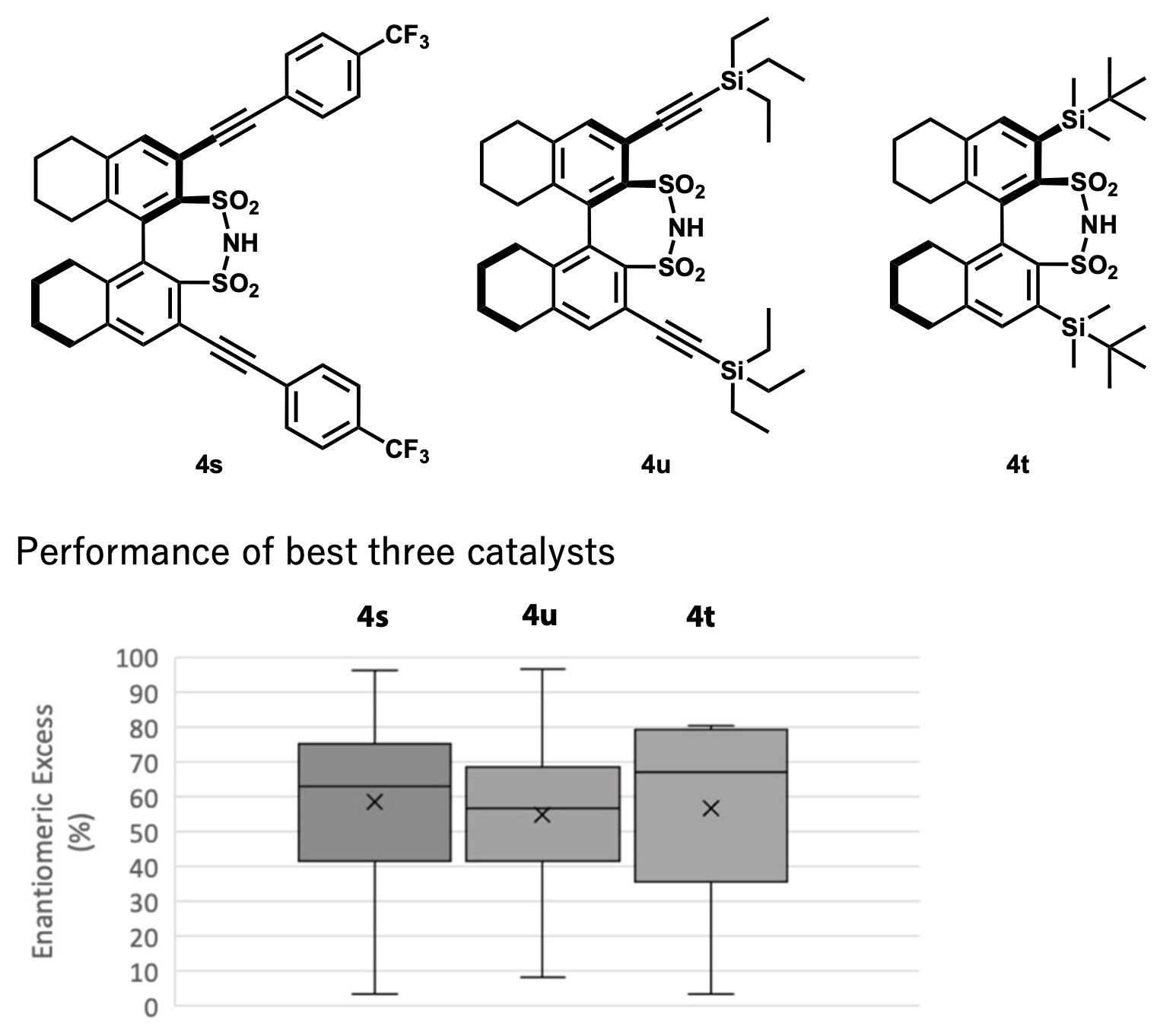
Figure 4 .Three catalysts proposed by machine learning. However, the expected substrate generality was lower than expected. Graph adapted from paper [1].
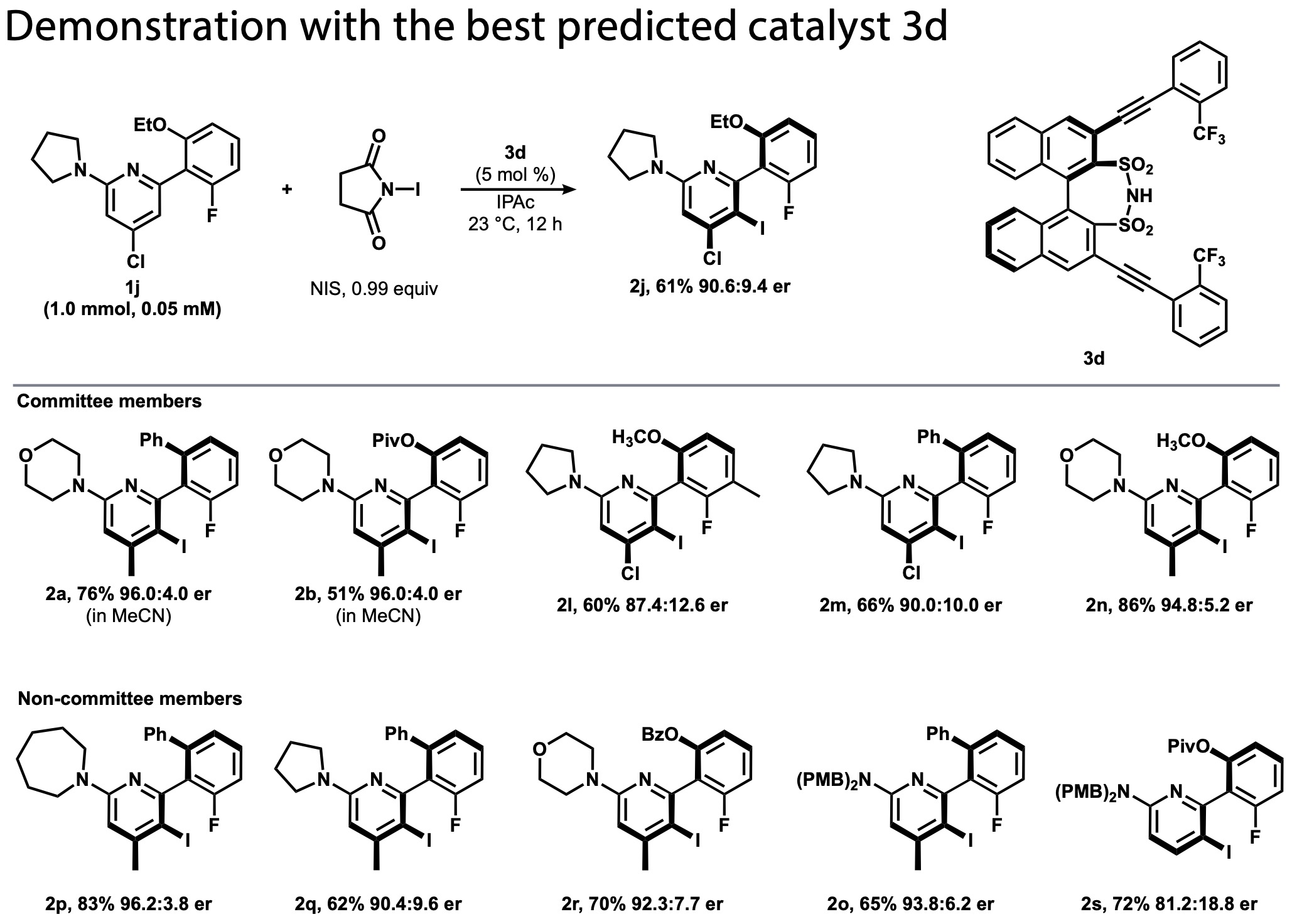
Figure 5: Substrate scope using the optimal catalyst 3d. Substrates other than voters in the lower row.
Comments
- Not only the successful results of trying to improve the catalyst by successfully using the previous report, but also the initial failures in its use and the process of solving them (e.g., devising a voting system) are suggestive of the idea of using machine learning in chemical research.
- To some extent, the type of reactions that are easy to apply are selected for verification. As a precondition for this method, a certain amount of experimentation is required, so it is necessary to have high-throughput reaction implementation and analysis methods available.
- As the research progresses, the calculation method and reaction conditions are being fine-tuned. Although the details are not clear, it is not difficult to understand this situation because of the time and labor involved.
References
- (a) Zahrt, A. F.; Henle, J. J.; Rose, B. T.; Wang, Y.; Darrow, W. T.; Denmark, S. E. Science 2019, 363, eaau5631. DOI: 10.1126/science.aau5631 (2) Reivew: Rinehart, N. I.; Zahrt, A. F.; Henle, J. J.; Denmark, S. E. Acc. Chem. Res. 2021, 54 , 2041-2054. DOI: 10.1021/acs.accounts.0c00826
- Original article of this blog in Japanese: https://www.chem-station.com/blog/2024/01/hldf.html